- Published on
ImaginaryCTF 2025 dinosaur write-up
- Authors

- Name
- Lazarus

This task was one of the most vexing challenges in ImaginaryCTF 2025. The title was simple, but the provided file, STEGosaurus.txt, pointed squarely at the infamous category: steganography. Even worse, the enormous text file full of repeated tokens suggested something hidden just beneath the surface - possibly requiring setting up a reconstruction site.
Category: Forensics
Points: 408
Solves: 34 out of 1414 teams
Author: Moaiman
Description: Everyone has a favorite dinosaur, can you guess mine?
Attachments: STEGosaurus.txt
Initial recon
The provided file is 468 kB and contains many repeated tokens:
imagine imagine imagine imagine rooOreos rooZyphen rooZyphen rooNobooliEt3rnos rooNobooliEt3rnos rooNobooliEt3rnos rooNobooliEt3rnos rooNobooliEt3rnos rooNobooliEt3rnos rooNobooliEt3rnos rooNobooliEt3rnos rooNobooliEt3rnos ...
While Stegosaurus is a real dinosaur, the filename STEGosaurus.txt also hints at steganography. Either these tokens encode data, or they compose an image when mapped to a visual representation.
It’s hard to identify all unique tokens by eye, so let's use Python to prepare some statistics:
from collections import Counter
import re
with open("STEGosaurus.txt", encoding='utf-8') as file:
word_counts = Counter(re.findall(r'\b\w+\b', file.read()))
print(f"Found {len(word_counts)} unique words.")
for word, count in word_counts.most_common():
print(f"{word}: {count}")
Sample output (truncated):
Found 47 unique words.
imagine: 10907
harold: 7824
rooOreos: 4121
rooFrozenVoid: 3984
rooRobin: 3889
rooNobooliEt3rnos: 3780
kek: 3049
skullfire: 2900
why: 2369
rooHeartEt3rnos: 1796
breadThink: 1493
rooZyphen: 815
rooSunNobooli: 533
roobamboo: 472
rooDevilEt3rnos: 434
psyduck: 416
...
Many tokens start with "roo". These resemble custom Discord emoji names, which can be typed as :emoji_name: to embed images. That suggests the tokens may correspond to server-specific emojis. Let's visit the ImaginaryCTF Discord channel.
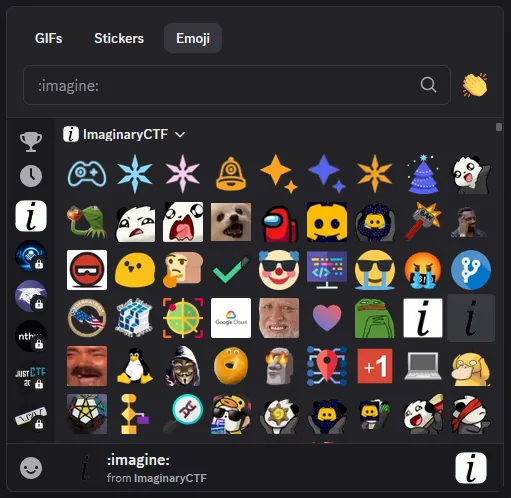
Indeed, the names are the same. This observation was the key to unlocking the next step.
The plan: map each token to the matching Discord emoji image and assemble a large mosaic that may reveal a message.
Preparing the emojis
We need to download emojis' images. Discord's UI is JavaScript-heavy, so the simplest approach is to paste all emoji shortcodes into a message draft, then grab the resulting HTML via Developer Tools.
Let's run our stats program again and format names into proper emoji tags:
python3 stats.py | awk -F: '/:/ {printf ":%s: ", $1}'
This awk command processes each line of the output from the Python script. It uses -F: to set the input field separator to a colon (:), so it treats each line as split into fields by colons. For each matched line, printf ":%s: ", $1 prints the first field $1 (the text before the first colon) wrapped in colons and followed by a space, without adding a newline.
We get a list:
:imagine: :harold: :rooOreos: :rooFrozenVoid: :rooRobin: :rooNobooliEt3rnos: :kek: :skullfire: :why: :rooHeartEt3rnos: :breadThink: :rooZyphen: :rooSunNobooli: :roobamboo: :rooDevilEt3rnos: :psyduck: :roowhim: :rooYayEt3rnos: :aaaaa: :rooRage: :2021_Snowsgiving_Emojis_002_Snow: :programmer: :thisisfine: :bigBrain: :rooHappy2: :gcloud: :rooPuzzler7: :rooCashEt3rnos: :rooAZ: :coolcry: :roomjkoo: :plus1: :rooHappy3: :puzzler7: :tirefireNervous: :732334696565964811: :max49: :astroZOOOOM: :Wut: :moaifire: :rooStephencurry: :rooBan: :rooSupport: :rooFrozen: :rooMaxNoBooli: :rooPingMad: :rooPuzzlerDevil:
Pasting this into the message box:
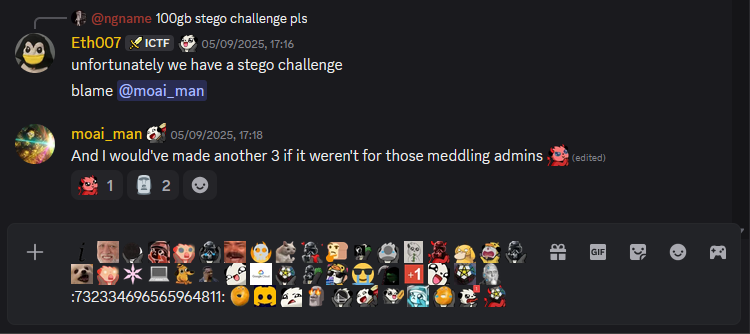
There is no :732334696565964811: emoji, but other than that, everything got converted into an image.
Inspecting the draft message content and copying inner HTML for <div data-slate-node="element">, we get a soup of tags. What we are interested in are ones in a form:
<img
aria-label=":imagine:"
class="emoji"
data-type="emoji"
data-id="871115444856160296"
alt=":imagine:"
draggable="false"
src="https://cdn.discordapp.com/emojis/871115444856160296.webp?size=44"
/>
This connects the emoji's name with a direct link to a file on Discord's Content Delivery Network (CDN) server.
Speaking of soup, let's use the Beautiful Soup library to extract the names and corresponding URL addresses. And, while we are at it, why not download them in the same loop:
import os
import requests
from bs4 import BeautifulSoup
file_name = "input_field.htm"
output_dir = "images"
os.makedirs(output_dir, exist_ok=True)
with open(file_name, 'r', encoding='utf-8') as file:
html_string = file.read()
soup = BeautifulSoup(html_string, 'html.parser')
for img in soup.find_all('img', class_='emoji'):
name = img.get('aria-label') or img.get('alt')
url = img.get('src')
if name and url:
clean_name = name.strip(':')
file_path = os.path.join(output_dir, f"{clean_name}.webp")
print(f"{name} -> {url}")
response = requests.get(url)
if response.status_code == 200:
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print(f"Failed to download {url} (status {response.status_code})")
Now we have the images downloaded into the images directory. There is a size indicator appended to the URL, and indeed, most of the emojis are in 44x44 size, but there are also some 44x43, 44x33 or 37x44.
Creating the image
Having the provided file with names and actual images, we can attempt to build a mosaic. We need to handle missing emojis and variations in image sizes.
We also need to deduce our final image size. Let's count the number of tokens in the provided file:
wc -w STEGosaurus.txt
50176 STEGosaurus.txt
Option -w is for counting words. Maybe the result can be squared:
awk 'BEGIN {print sqrt(50176)}'
224
Nice, it looks like an image of size 224x224 will use exactly all the tokens. Are there any other pairs valid? Yes, you can look for integer factor pairs of that number:
import math
total_pixels = 50176
for i in range(1, math.isqrt(total_pixels) + 1):
if total_pixels % i == 0:
print(f"{i}x{total_pixels // i}", end=" ")
This outputs the following pairs, and you can also swap width and height:
1x50176 2x25088 4x12544 7x7168 8x6272 14x3584 16x3136 28x1792 32x1568 49x1024 56x896 64x784 98x512 112x448 128x392 196x256 224x224
What we're gonna do here is parse the input file, read the corresponding image or use a black square if not found. Compute tile position and mix it properly with a black background if it uses transparency. Generate the mosaic image and save it.
import os
import math
from PIL import Image
TOKENS_FILE = "STEGosaurus.txt"
OUTPUT_FILE = "mosaic.png"
IMAGES_DIR = "images"
TILE_SIZE = 44
TILES_PER_ROW = 224
def get_tile(token):
path = os.path.join(IMAGES_DIR, f"{token}.webp")
if not os.path.exists(path):
return None
img = Image.open(path).convert("RGBA")
if img.size != (TILE_SIZE, TILE_SIZE):
img = img.resize((TILE_SIZE, TILE_SIZE))
return img
def black_tile():
return Image.new("RGBA", (TILE_SIZE, TILE_SIZE), (0, 0, 0, 255))
def make_mosaic(tokens):
n = len(tokens)
rows = math.ceil(n / TILES_PER_ROW)
canvas = Image.new("RGBA", (TILES_PER_ROW * TILE_SIZE, rows * TILE_SIZE), (0, 0, 0, 255))
cache = {}
for idx, token in enumerate(tokens):
x = (idx % TILES_PER_ROW) * TILE_SIZE
y = (idx // TILES_PER_ROW) * TILE_SIZE
tile = cache.get(token)
if tile is None:
tile = get_tile(token) or black_tile()
cache[token] = tile
canvas.paste(tile, (x, y))
return canvas
tokens = open(TOKENS_FILE, "r", encoding="utf-8").read().split()
mosaic = make_mosaic(tokens)
mosaic.convert("RGB").save(OUTPUT_FILE)
print(f"Saved mosaic as {OUTPUT_FILE}")
...and we end up with 9856x9856 image built from 50176 44x44 emojis!

This is a bit of overkill. By setting the TILE_SIZE to 1, we can effectively convert each emoji into a single pixel, with its colour being the average of the original emoji's colours. This approach is much more effective than using the full 44x44 emojis, which created an overly detailed image.

That's better. We also got rid of patterns made by emojis' details. So, we have a dinosaur with a QR code, probably with an encoded flag. Quick scan with a QR app and... nothing, it's unrecognisable. Well, here we go again!
Recovering the QR code
The image is too noisy and inconsistent, with some of the black and white modules being corrupted.

The code appears to be a Version 3 QR (29×29 modules), which aligns with standard sizing for small payloads, but noise and inconsistent module shapes break decoders. Manual cleanup is needed.
There are many possible filter combinations to enhance the image.
We can use GIMP or any similar tool. Let's use Filters / Enhance / Noise Reduction, strength 32, to smooth the pixels. Another filtering with Colors / Tone Mapping / Mantiuk 2006, contrast 1.0, saturation 0.0, and we increase local contrast. The core structure of the QR code became clearer.


Using a square pencil tool set to module size, it is possible to redraw the corrupted areas, converting them to pure black and white pixels. This process ensured that the QR code was fully compliant with the standard.


Once the QR code was fully restored, a quick scan with a mobile app revealed the flag: ictf{get_baited_its_actually_an_ankylosaurus}. Now we know what we dug up - it was ankylosaurus all along!
Summary
Despite initial reservations about stego, this turned out to be a genuinely fun, well-crafted challenge that rewarded persistence and careful reconstruction. A clever emoji-to-mosaic pipeline concealed a noisy QR that ultimately yielded to manual restoration and a satisfying reveal.
If you are interested in an afterparty exercise, explore generating photomosaics from small images: how to compute each tile's average colour in a perceptual space, and arrange a grid that approximates the larger image.
Lastly, kudos for making this task AI-resistant. Sometimes, the most effective tool in a CTF is a bit of patience and careful manual effort.
This write-up was originally published on mariuszbartosik.com and is reproduced here with permission from the author.