- Published on
Player 2 / crypto - PL
Wstęp
Między piątkiem 12 czerwca 2026, 22:00 CEST, a wtorkiem 16 czerwca 2026, 05:59 CEST odbył się boroCTF 2026. CTF trwał około 80 godzin i miał około 114 zadań. Piszę "około", bo nie śledziłem, czy któreś zadania zostały zdjęte w trakcie zawodów.
Zadania były dość różnorodne. Było sporo OSINT-u, trochę zgadywanek i dużo prostszych zadań, z którymi agenty AI radziły sobie bardzo szybko. Były też jednak takie, gdzie samo odpalenie modelu nie wystarczało i trzeba było połączyć automatyzację z ręczną analizą. Jednym z takich zadań było Player 2.
Opis zadania
Zadanie należało do kategorii crypto, było wyceniane na 300 punktów, mimo że na pierwszy rzut oka wyglądało jak forensics albo video-stego.
Dostaliśmy link do filmu na YouTube. Na filmie widać gameplay i overlay z kontrolerem PlayStation. Ważna była druga wersja filmu, bo pierwsza była poprawiana w trakcie CTF-a.
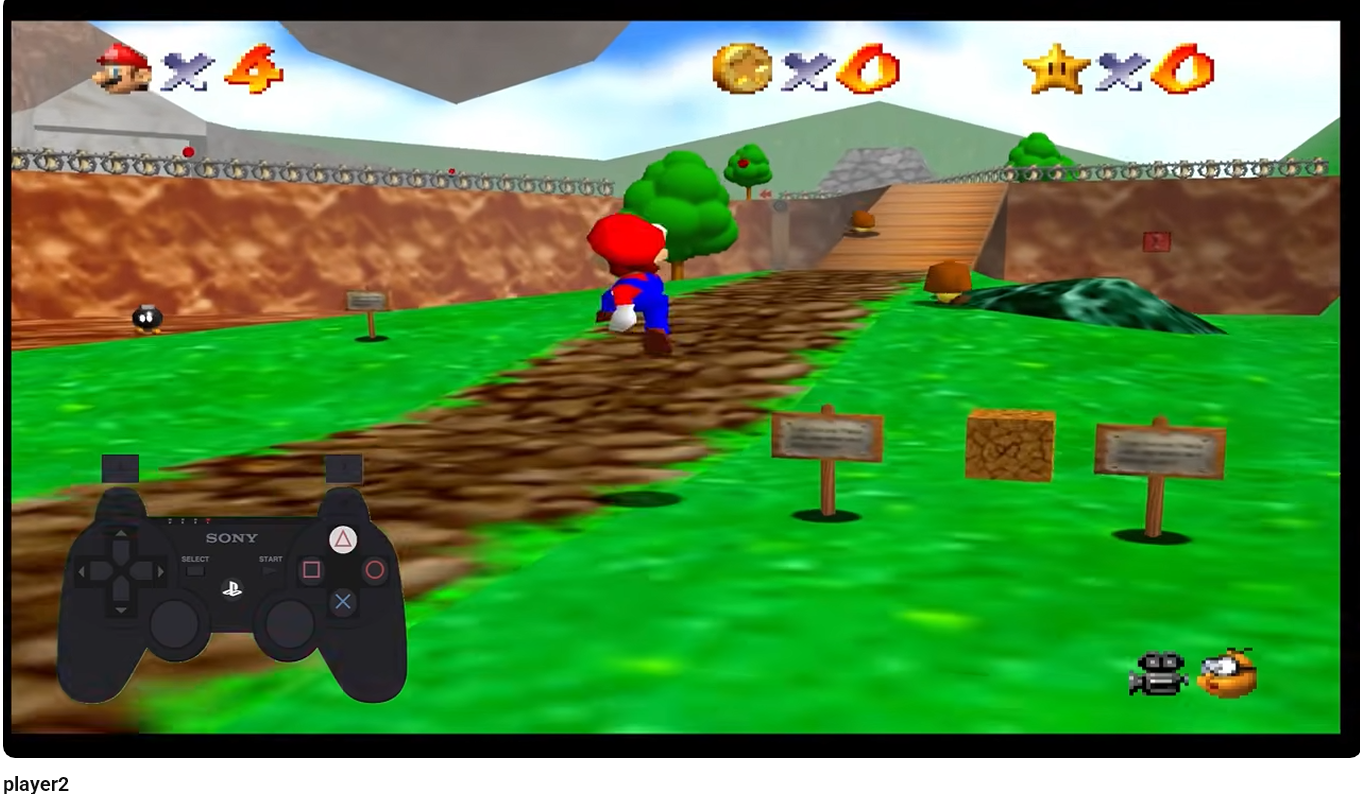
Najważniejsza obserwacja była prosta: skoro widać kontroler, to dane najpewniej są zakodowane w kolejnych naciśnięciach przycisków. Film nie był właściwą warstwą steganograficzną. Był tylko nośnikiem sekwencji inputów.
Ekstrakcja wideo i klatek
Film pobrałem z YouTube w ten sposób:
yt-dlp -f 136 https://www.youtube.com/watch?v=dthKN5GNPOU
Potem wyciąłem sam obszar z kontrolerem:
ffmpeg -i wejscie.mp4 -vf "crop=330:234:50:434" -c:a copy pad_wycinek.mp4

Następnie rozbiłem wycinek na klatki. Klatek było ponad 6000, więc ręczne przeglądanie wszystkiego nie miało sensu. Pierwszy etap polegał na odrzuceniu klatek bez naciśniętego przycisku.
Do tego powstał prosty skrypt analizujący różnice pikseli względem klatki bazowej bez wciśnięcia. Skrypt patrzył tylko na obszary konkretnych przycisków, żeby ignorować ruchome tło. To działało wystarczająco dobrze jako filtr, ale nie jako idealny klasyfikator.
Po odfiltrowaniu pustych klatek trzeba było jeszcze zgrupować serie kolejnych klatek tego samego naciśnięcia. Jeżeli np. jedno naciśnięcie trwało od frame_0063.png do frame_0067.png, zostawialiśmy jeden reprezentatywny obrazek z tej serii.
Po czyszczeniu zostały 164 naciśnięcia i jeden pusty/specjalny obrazek.
Problemy z automatycznym odczytem
Na tym etapie zaczęły się błędy. Automat był przydatny, ale nie można było mu zaufać bez kontroli człowieka.
Największy problem sprawiał triangle. Czasem nie wyglądał jak jasne wypełnienie całego przycisku, tylko jak subtelna zmiana symbolu albo obwódki. Prosty próg różnicy pikseli łapał go słabo albo mylił z tłem.
Ręcznie oznaczone klatki, które wymagały szczególnej uwagi przy triangle:
082, 118, 619, 1695, 1973, 3537, 3743, 3968, 4301, 4733, 5347
Drugim problemem były shouldery: L1, L2, R1, R2. Są na górze kontrolera, a ich podświetlenia łatwo pomylić, szczególnie kiedy pracuje się na wycinku filmu, a nie na idealnym obrazie kontrolera.
To później okazało się kluczowe, bo w poprawnym rozwiązaniu shouldery nie są samodzielnymi znakami. One modyfikują następny przycisk. Pomyłka w jednym shoulderze potrafi przesunąć całe dekodowanie.
Pierwsza sekwencja przycisków
Po pierwszym czyszczeniu miałem taką roboczą sekwencję:
R1 triangle R2 triangle L1 down up L1 square R1 start L1 up R1 cross start R1 down L2 down triangle L1 circle L2 cross L1 circle up R1 circle L1 start L1 left L1 square L2 start left L2 down R1 circle R2 cross L2 down R2 triangle R1 circle R1 up R2 cross L1 triangle L1 up right L2 down left L1 circle R2 up R1 down right R1 right down L1 circle L1 square R2 R1 circle up L1 cross L1 circle start L2 cross R2 circle R1 down R2 up L1 triangle R1 start L1 triangle up R1 down L1 triangle left up circle R2 circle R1 down R2 triangle L1 square R1 start left R1 left R2 triangle L1 square cross up R1 start L1 square left L2 down L2 R1 circle R1 square triangle L2 square start L1 square R1 start R1 right down L1 circle R1 left square down L2 cross L2 cross R1 circle R1 square
Na początku wyglądało to zachęcająco, bo pierwsze symbole można było próbować dopasować do boroCTF. Przykładowo:
001 R1 -> b
002 triangle -> o
003 R2 -> r
004 triangle -> o
005 L1 -> C
006 down -> T
007 up -> F
To był kuszący trop, ale dość szybko zaczął się sypać.
Ślepy trop: bezpośrednie mapowanie na boroCTF
Pierwsza hipoteza była taka, że surowe naciśnięcia zaczynają się bezpośrednio od tekstu:
boroCTF{
Jeśli 1 przycisk = 1 znak, to początek da się dopasować ręcznie, ale nie wynika z tego stabilna tabela. Ten sam przycisk musiałby znaczyć różne rzeczy w różnych miejscach.
Sprawdzaliśmy więc warianty bitowe i heksadecymalne.
Jeden przycisk jako nibble
Jeżeli każdy przycisk byłby jednym niblem, to dla początku boro:
b = 0x62: R1 -> 6, triangle -> 2
o = 0x6f: R2 -> 6, triangle -> f
Już tutaj jest konflikt: triangle musiałby oznaczać raz 2, a raz f.
Jeden przycisk jako 2 bity
Sprawdziliśmy też model, w którym jeden przycisk daje 2 bity, czyli cztery przyciski tworzą jeden bajt.
Dla litery b:
b = 0x62 = 01100010
R1 -> 01
triangle -> 10
R2 -> 00
triangle -> 10
Dla kolejnych liter pojawiały się kolejne konflikty. R1, L1 i inne przyciski musiałyby zmieniać znaczenie zależnie od pozycji. To nie wyglądało jak prosty alfabet ani proste kodowanie bitowe.
Wniosek: format flagi mówi, jak wygląda finalny wynik, ale surowa sekwencja przycisków raczej nie zaczyna się plaintextem boroCTF{.
Ślepy trop: pary przycisków jako nibble
Kolejny trop wynikał z długości sekwencji:
164 naciśnięcia / 2 / 2 = 41 bajtów
To sugerowało model:
2 naciśnięcia = 1 hex nibble
4 naciśnięcia = 1 bajt
Dla założonego początku boroCTF{ dało się przypisać pary do nibbli:
R1+triangle -> 6
R2+triangle -> 2
L1+down -> 6
up+L1 -> f
square+R1 -> 7
start+L1 -> 2
up+R1 -> 6
cross+start -> f
R1+down -> 4
L2+down -> 3
triangle+L1 -> 5
circle+L2 -> 4
cross+L1 -> 4
circle+up -> 6
R1+circle -> 7
L1+start -> b
To dawało:
62 6f 72 6f 43 54 46 7b
czyli dokładnie boroCTF{.
Problem był taki, że ta tabela nie działała dalej. W całej sekwencji było 82 pary i aż 55 unikalnych par. Nie wyglądało to jak stabilne mapowanie para -> nibble. Bardziej przypominało dopasowanie początku na siłę.
Ślepy trop: layout PSX/PS2 jako hex
Pad PlayStation ma naturalny układ bitmaski, który można zmapować do wartości 0..f:
select -> 0
L3 -> 1
R3 -> 2
start -> 3
up -> 4
right -> 5
down -> 6
left -> 7
L2 -> 8
R2 -> 9
L1 -> a
R1 -> b
triangle -> c
circle -> d
cross -> e
square -> f
Po takim mapowaniu sekwencja dawała hex:
bc9ca64afb3a4be3b686cad8ead4bda3a7af83786bd9e869cbdb49eaca45867ad94b65b56adaf9bd4aead38e9db694acb3ac4b6ac74d9db69cafb37b79cafe4b3af7868bdbfc8f3afb3b56adb7f68e8ebdbf
Po złożeniu po dwa nible w bajty nie było sensownego tekstu:
...J.:K............xk..i..I..E.z.Ke.j...J.........Kj.M.....{y..K:......:.;V.......
Po zamianie kolejności nibbli w bajcie też nie było plaintextu:
..j....>kh...M.:z.8..........Th...V[......=..kI.;...|..k..;.......h.......e.{o....
Ten trop też odpadł.
Dlaczego się motaliśmy
Największym błędem było przywiązanie się do założenia, że początek musi bezpośrednio kodować boroCTF{. To był naturalny punkt zaczepienia, ale w tym zadaniu format flagi nie był cribem do pierwszej warstwy.
Drugi błąd to zbyt duże zaufanie do automatycznej klasyfikacji klatek. Skrypt dobrze filtrował puste klatki, ale mylił subtelne naciśnięcia, szczególnie triangle, oraz nie dawał pełnej pewności przy shoulderach.
Trzeci problem był bardziej semantyczny: próbowaliśmy traktować przyciski jak zwykły alfabet, bajty albo nible. Dopiero później okazało się, że niektóre przyciski mają rolę modyfikatorów, a nie samodzielnych symboli.
Fałszywe olśnienie: P2 to TALK, ale z błędną sekwencją
Prawdziwy kierunek pojawił się dopiero przy skojarzeniu tytułu Player 2 z systemem P2 to TALK z Giftscop/Petscop:
https://giftscop.com/etc/p2_to_talk
W tym systemie przyciski kontrolera kodują fonemy. Shouldery (L1, L2, R1, R2) stoją przed przyciskiem bazowym i wybierają inną kolumnę fonemów. Niektóre kombinacje są puste, czyli dają null. To pasowało do Player 2 i do słowa nulled.
Na początku jednak nadal mieliśmy błędną albo niepełną sekwencję. Po zdekodowaniu P2-to-TALK wyszedł fonetyczny tekst, który dało się na siłę segmentować jako:
behind you of course right one checked failure ...
Na tym etapie myślałem, że ten początek to szum i chciałem go zignorować. Brzmiało po angielsku, ale nie było jeszcze jasne, jak łączy się z finalną flagą. Problem w tym, że kilka brakujących lub nadmiarowych inputów oraz źle zorientowane shouldery przesuwały fonemy. Model słownikowy próbował dopasować je do znanych słów i dlatego wychodziły sensownie brzmiące, ale częściowo błędne frazy.
Najlepszy przykład to początek b ih h i n d, który bardzo łatwo zinterpretować jako behind. Dopiero na samym końcu, kiedy reszta akrostychu zaczęła się dobrze układać, okazało się, że ten początek nie był śmieciem: dawał prefix boroCTF.
Korekta sekwencji
Przełom przyszedł po porównaniu naszej sekwencji z ręczną rozpiską znaków od JohnaDoersa. Przepisał inputy z filmu niezależnie od automatu. W jego notacji x oznaczało cross, a nazwy typu r1, l2, triangle, circle były po prostu kolejnymi naciśnięciami pada.
Pełna rozpiska JohnaDoersa wyglądała tak:
r2 triangle r1 triangle l2 down up l2 square r2
start l2 up r2 x
start r2 down l1 down triangle l2 circle l1 x l2 circle up r2 circle l2 l2 left l2 square
l1 start left l1 down r2 circle r1 x l1 down r1 triangle r2 circle r2 up r1 x l2 triangle l2 up right l1 down left l2 circle r1 up r2 down right r2 right down l2 circle l2 square r1 up r2 circle up l2 x l2 circle start l1 x r1 circle r2 down r1 up l2 triangle r2 start l2 triangle up r2 down l2 triangle left
r2 up r2 circle r1 circle r2 down r1 triangle l2 square r2 start
left r2 left r1 triangle l2 square l1 x up r2 start l2 square left l1 down l1 x r2 circle r2 square triangle l1 square start l2 square r2 start right r2 right down l2 circle r2 left square l2 square l1 down l1 x l1 x r2 circle x r2 square
Po normalizacji nazw przycisków okazało się, że sekwencje prawie się zgadzają, ale nasza wymagała zamiany shoulderów:
L1 <-> L2
R1 <-> R2
Zgodność po takim przestawieniu była bardzo wysoka, około 0.967, ale zostało kilka różnic: jedno start wyglądało na nadmiarowe, a w paru miejscach brakowało tokenów. To wystarczyło, żeby wcześniejsze P2-to-TALK dawało mylące słowa.
Po poprawieniu sekwencji P2-to-TALK nie dawało już przypadkowego tekstu do czytania wprost. Zaczęły wychodzić grupy słów, których pierwsze litery miały sens.
Poprawne rozwiązanie
Właściwy strumień należy czytać jako fonemy P2-to-TALK, a potem segmentować w słowa. Tu wcześniej był łatwy do przeoczenia skrót myślowy: rozpiska JohnaDoersa nie zamienia się bezpośrednio w litery flagi. Najpierw trzeba łączyć shouldery z następnym przyciskiem bazowym.
Przykład z samego początku rozpiski JohnaDoersa:
r2 triangle r1 triangle l2 down up l2 square r2 start
Po P2-to-TALK daje:
R2+triangle -> b
R1+triangle -> ih
L2+down -> h
up -> i
L2+square -> n
R2+start -> d
czyli fonetycznie:
b ih h i n d -> behind
To właśnie dlatego przez chwilę wyglądało, że wiadomość zaczyna się od behind you.... Początkowo chciałem ten fragment odrzucić, ale po pełnej analizie okazało się, że jest początkiem akrostychu.
Pierwszy fragment daje prefix flagi:
b ih h i n d y oo -> behind you -> B
uh v c aw r s -> of course -> O
r i t -> right -> R
u n -> one -> O
ch eh c -> check -> C
t ay c ih t -> take it -> T
f ay l y er -> failure -> F
Akrostych zaczyna się więc od samego początku, a nie od tokenu 060. Token 060 jest miejscem, od którego zaczyna się body flagi. W surowej rozpisce JohnaDoersa jest to l1 w tym fragmencie:
055 l2
056 triangle
057 l2
058 up
059 right
060 l1
061 down
062 left
063 l2
064 circle
Po P2-to-TALK:
055-056 L2+triangle -> l
057-058 L2+up -> y
059 right -> er
zamyka wcześniejsze słowo failure, a od następnych inputów zaczyna się body flagi:
060-061 L1+down -> c
062 left -> eh
063-064 L2+circle -> r
czyli:
c eh r -> care -> C
Pełniejsze parsowanie rozpiski JohnaDoersa wyglądało tak. Numer po lewej to numer tokenu w surowej sekwencji JohnaDoersa, a nie numer klatki:
001-002 R2+triangle -> b
003-004 R1+triangle -> ih
005-006 L2+down -> h
007 up -> i
008-009 L2+square -> n
010-011 R2+start -> d
012-013 L2+up -> y
014-015 R2+cross -> oo
016 start -> uh
017-018 R2+down -> v
019-020 L1+down -> c
021 triangle -> aw
022-023 L2+circle -> r
024-025 L1+cross -> s
026-027 L2+circle -> r
028 up -> i
029-030 R2+circle -> t
031 L2 -> samotny shoulder, pominięty
032-033 L2+left -> u
034-035 L2+square -> n
036-037 L1+start -> ch
038 left -> eh
039-040 L1+down -> c
041-042 R2+circle -> t
043-044 R1+cross -> ay
045-046 L1+down -> c
047-048 R1+triangle -> ih
049-050 R2+circle -> t
051-052 R2+up -> f
053-054 R1+cross -> ay
055-056 L2+triangle -> l
057-058 L2+up -> y
059 right -> er
060-061 L1+down -> c <- od tego miejsca zaczyna się body flagi
062 left -> eh
063-064 L2+circle -> r
065-066 R1+up -> oh
067-068 R2+down -> v
069 right -> er
070-071 R2+right -> dh
072 down -> air
073-074 L2+circle -> r
075-076 L2+square -> n
077-078 R1+up -> oh
079-080 R2+circle -> t
081 up -> i
082-083 L2+cross -> m
084-085 L2+circle -> r
086 start -> uh
087-088 L1+cross -> s
089-090 R1+circle -> ee
091-092 R2+down -> v
093-094 R1+up -> oh
095-096 L2+triangle -> l
097-098 R2+start -> d
099-100 L2+triangle -> l
101 up -> i
102-103 R2+down -> v
104-105 L2+triangle -> l
106 left -> eh
107-108 R2+up -> f
109-110 R2+circle -> t
111-112 R1+circle -> ee
113-114 R2+down -> v
115-116 R1+triangle -> ih
117-118 L2+square -> n
119-120 R2+start -> d
121 left -> eh
122-123 R2+left -> th
124-125 R1+triangle -> ih
126-127 L2+square -> n
128-129 L1+cross -> s
130 up -> i
131-132 R2+start -> d
133-134 L2+square -> n
135 left -> eh
136-137 L1+down -> c
138-139 L1+cross -> s
140-141 R2+circle -> t
142-143 R2+square -> p
144 triangle -> aw
145-146 L1+square -> z
147 start -> uh
148-149 L2+square -> n
150-151 R2+start -> d
152 right -> er
153-154 R2+right -> dh
155 down -> air
156-157 L2+circle -> r
158-159 R2+left -> th
160 square -> a
161-162 L2+square -> n
163-164 L1+down -> c
165-166 L1+cross -> s
167-168 L1+cross -> s
169-170 R2+circle -> t
171 cross -> ah
172-173 R2+square -> p
Poprawka względem rozpiski JohnaDoersa była więc mała, ale ważna: token 031, czyli samotny l2, nie ma sensu w P2-to-TALK, bo shoulder powinien modyfikować kolejny przycisk bazowy. Traktowaliśmy go jako nadmiarowy odczyt i pomijaliśmy. Po tej korekcie początek dawał BOROCTF, a część od tokenu 060 dawała body flagi.
Kluczowa nie była pełna treść zdania, tylko pierwsze litery kolejnych słów albo krótkich fraz. over there liczyliśmy jako frazę zaczynającą się na O, a under there jako frazę zaczynającą się na U.
Dla przykładu, kilka pierwszych poprawnych przejść z finalnego fragmentu wyglądało tak:
L1+down left L2+circle -> c eh r -> care -> C
R1+up R2+down right R2+right down L2+circle
-> oh v er dh air r -> over there -> O
L2+square R1+up -> n oh -> no -> N
R2+circle up L2+cross -> t i m -> time -> T
To pokazuje, dlaczego sam ciąg fonemów nie był jeszcze flagą. Trzeba było najpierw złożyć fonemy w słowa, a potem wziąć ich pierwsze litery.
Grupa prefixu:
b ih h i n d y oo -> behind you -> B
uh v c aw r s -> of course -> O
r i t -> right -> R
u n -> one -> O
ch eh c -> check -> C
t ay c ih t -> take it -> T
f ay l y er -> failure -> F
Akrostych:
BOROCTF
Pierwsza grupa body:
c eh r -> care -> C
oh v er dh air r -> over there -> O
n oh -> no -> N
t i m -> time -> T
r uh s ee v -> receive -> R
oh l d -> old -> O
l i v -> live -> L
l eh f t -> left -> L
ee v ih n -> even -> E
d eh th -> death -> D
Akrostych:
CONTROLLED
Druga grupa:
ih n s i d -> inside -> I
n eh c s t -> next -> N
p aw z -> pause -> P
uh n d er dh air r -> under there -> U
th a n c s -> thanks -> T
s t ah p -> stop -> S
Akrostych:
INPUTS
Razem daje to:
BOROCTF CONTROLLED INPUTS
Zgodnie z formatem zadania oraz dopiskiem No _ between words, finalna flaga wynika bezpośrednio z prefixu BOROCTF oraz dwóch słów body zapisanych bez spacji i bez podkreślenia.
Flaga:
boroCTF{controlledinputs}
Podsumowanie
To zadanie wyglądało jak analiza wideo, ale finalnie było zadaniem o specyficznym kodowaniu inputów. Wideo służyło tylko do przeniesienia sekwencji przycisków. To była owocna współpraca człowieka z agentem AI. Człowiek wyciął obrazki, znalazł metodę, reszte dopasowała sztuczna inteligencja.
Najważniejsze kroki:
- Pobrać film i wyciąć overlay z kontrolerem.
- Odfiltrować puste klatki i zgrupować serie tego samego naciśnięcia.
- Ręcznie poprawić problematyczne przyciski, szczególnie
triangleoraz shouldery. - Odrzucić proste mapowania na
boroCTF, nible, bity i layout PSX. - Rozpoznać
Player 2jako wskazówkę do P2-to-TALK. - Poprawić orientację shoulderów i brakujące/nadmiarowe inputy.
- Zdekodować fonemy, wziąć akrostych
BOROCTF CONTROLLED INPUTSi zastosować format flagi.